Here's what the final system did: given a search query, it returned ranked results from a crawled web corpus in under a second. No external search library, no Elasticsearch — just Java, a custom key-value store, and 44 EC2 instances wired together inside a private AWS VPC.
This is MiniSearch, the final project for CIS 5550 (Distributed Systems) at Penn.
Architecture
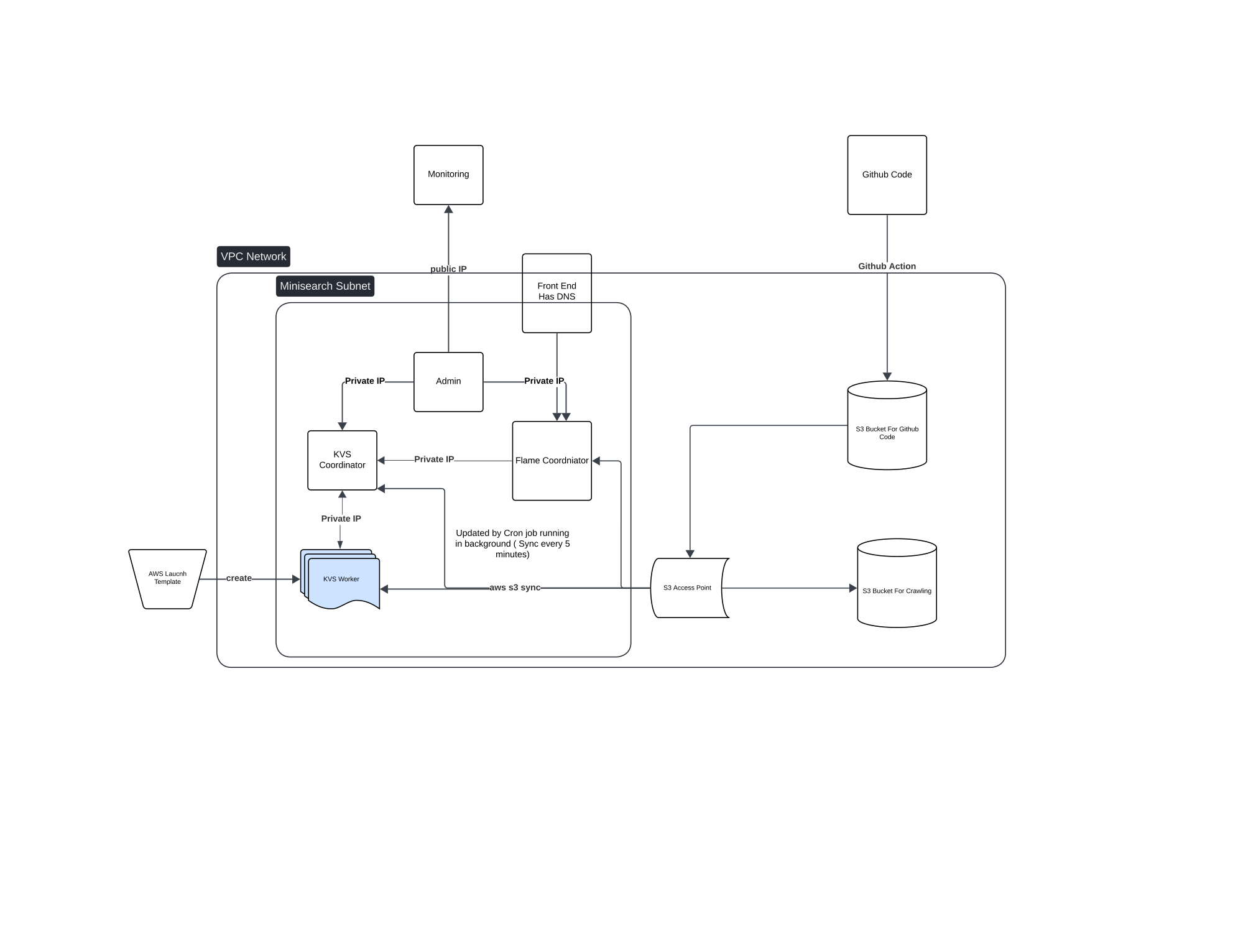
The system has four major components, each running as a separate fleet on the cluster:
Web Crawler — multi-threaded, URL-frontier-based crawler that fetched and stored raw HTML into a distributed key-value store. It deduplicates URLs, follows robots.txt, and pipelines fetches across thread pools.
Indexer — MapReduce-style pipeline reading from the KVS crawl store, tokenizing documents, and building an inverted index. Each (term, docId) pair gets a TF-IDF score computed and stored back to KVS.
PageRank — iterative link-graph ranker running over the crawled URL graph stored in KVS. Each iteration reads the full adjacency list, computes damped rank propagation, and writes updated scores. Converges in ~10 iterations.
Query Frontend — HTTP server that accepts search queries, intersects postings lists from the inverted index, multiplies TF-IDF × PageRank, and returns top-k ranked results with snippets.
The storage substrate for everything is a custom KVS (Key-Value Store) — a consistent-hash-based distributed store we built from scratch. No Redis, no DynamoDB. One coordinator routes keys across a pool of worker nodes using consistent hashing.
Infrastructure Layout
VPC (Minisearch Subnet)
├── KVS Coordinator (1 node — routes requests, tracks ring topology)
├── KVS Workers (AWS Launch Template — horizontally scaled)
├── Flame Coordinator (1 node — job scheduler / MapReduce master)
├── Admin Node (SSH entrypoint, ops tooling)
├── Frontend (1 node — DNS-terminated, serves search queries)
└── Monitoring (Prometheus + metrics collectors)
S3 (Code Bucket) ← GitHub Actions pushes here on every commit
S3 (Crawl Data Bucket) ← Raw HTML snapshots from crawler
S3 Access Point ← Workers pull and sync via cron every 5 minTotal: 44 EC2 instances split across crawler workers, indexer workers, KVS nodes, and coordinators.
The deploy pipeline: push to GitHub → Actions runs tests → zips source and uploads to S3 → a cron job on each worker pulls and reloads every 5 minutes. No need to SSH into individual workers.
The KVS Layer
The custom KVS is what made everything else composable. It exposes a simple HTTP API:
PUT /key → store value
GET /key → retrieve value
CPUT /key → conditional put (swap if old value matches)
APPEND /key → append to existing valueKeys are sharded across nodes using consistent hashing. The coordinator holds the ring topology. Workers register on startup. When a key maps to a dead node, the coordinator reroutes to the next live replica.
Both the crawler and indexer read and write exclusively through this layer, which let us scale storage independently of compute and swap out storage backends without touching application code.
PageRank Implementation
PageRank over a distributed graph requires reading the full link adjacency repeatedly. The key insight: store the adjacency list and current rank for each URL in KVS, then run a MapReduce job that:
- Map — for each source URL, emit
(destination, rank / out_degree)for every outbound link - Reduce — for each destination, sum all incoming contributions, apply damping:
0.15 + 0.85 * sum
After ~10 iterations the ranks stabilize. The final scores are stored back to KVS and joined with TF-IDF scores at query time.
Lessons
Building search from first principles makes the math concrete. The ranking formula isn't abstract — you see the link graph in your KVS, watch scores converge across iterations, and trace exactly why one URL outranks another.
The harder lesson was operational: with 44 nodes, something is always degraded. The S3-pull deploy strategy meant a flaky worker didn't block rollouts and didn't require coordinating SSH across dozens of machines. The crawler kept running; the indexer kept indexing; the system kept serving — independently of whether any individual deploy was in-flight.