Raft is a consensus algorithm designed to be understandable. Its paper — "In Search of an Understandable Consensus Algorithm" (Ongaro & Ousterhout, USENIX ATC 2014) — lays out every state transition explicitly. Implementing it anyway takes longer than expected.
Source: github.com/YuqiaoSu/Raft-Distributed-Key-Value-Database
What Raft Does
A Raft cluster is a group of replicas that agree on an ordered log of commands. Any replica can fail and rejoin; as long as a majority (floor(N/2) + 1) are alive, the cluster makes progress. The log is the database — applying committed entries in order produces the key-value state.
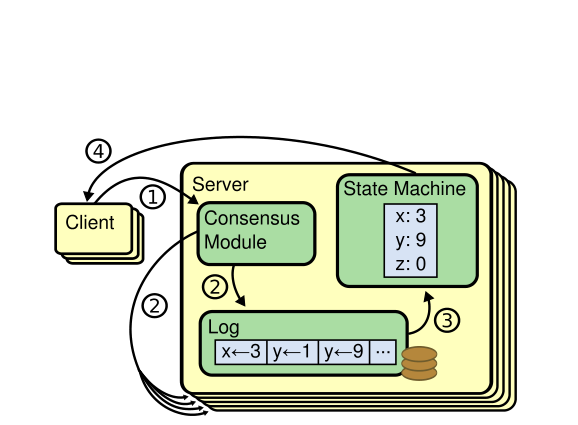
Three roles:
- Follower — passive, processes RPCs from leader and candidates
- Candidate — running for election; needs majority votes to win
- Leader — handles all client writes, replicates to followers
Leader Election
Each replica runs an election timer, reset whenever it hears from a valid leader:
self.election_timeout = random.randint(150, 300) * 0.01 # 150–300msThe randomized range is the key insight. If all nodes had the same timeout, they'd all become candidates simultaneously and split votes forever. Randomization means one node almost always fires first, wins quickly, and suppresses the others.
When the timer fires with no leader heartbeat:
def start_election(self):
self.state = "Candidate"
self.current_term += 1
self.voted_for = self.id
self.votes_received = {self.id}
self.reset_election_timer()
self.broadcast_request_vote()A candidate sends RequestVote RPCs to all peers. Each peer grants at most one vote per term (first-come-first-served, with a log-freshness check). When a candidate collects votes from a majority:
if len(self.votes_received) > len(self.peers) // 2:
self.become_leader()Heartbeats and Log Replication
The leader sends heartbeats every 250ms to suppress follower elections:
self.heartbeat_timeout = 0.25 # secondsEach AppendEntry RPC carries a consistency check — prevLogIndex and prevLogTerm. A follower only accepts the new entry if its log matches at that position.
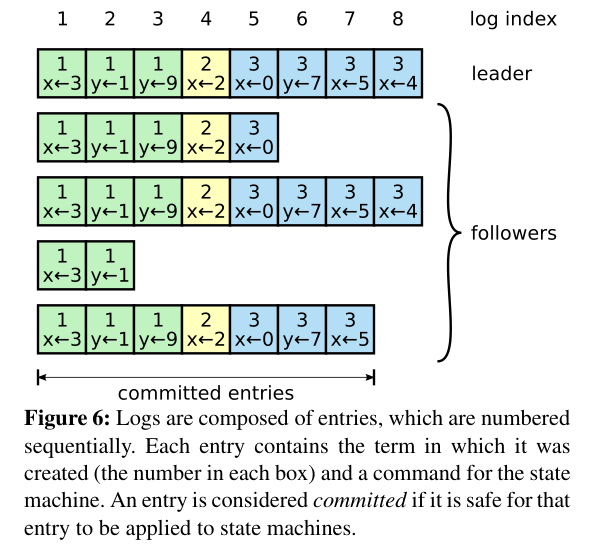
Client writes go through the leader, which appends to its log and replicates:
def append_entry(self, command):
entry = LogEntry(term=self.current_term, command=command)
self.log.append(entry)
self.pending_requests[len(self.log) - 1] = command
self.replicate_to_followers()Commit and Majority Quorum
An entry is committed when the leader has acknowledgment from a majority of replicas:
def check_commit(self):
for index in sorted(self.pending_requests.keys()):
acks = sum(
1 for peer_next in self.next_index.values()
if peer_next > index
)
if acks > len(self.peers) // 2:
self.commit_index = index
self.apply_committed()Only then does the leader reply to the client.
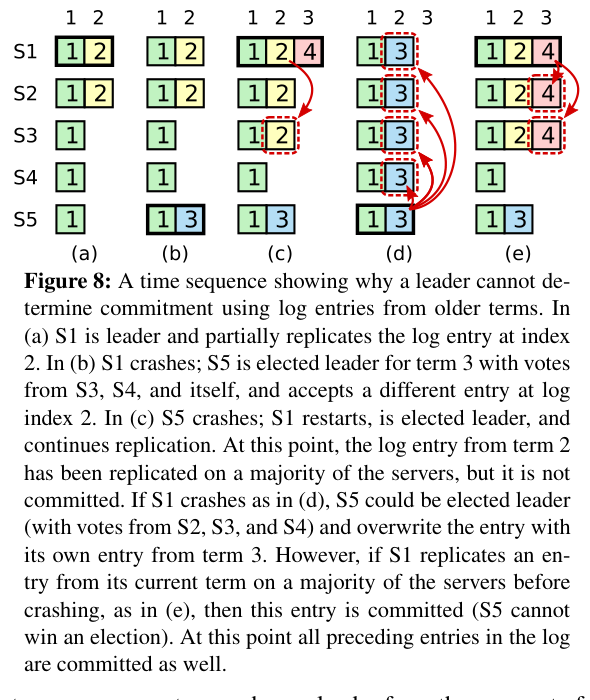
This is what makes Raft safe: a committed entry has been written to a majority of logs. Any future leader must have won election from a majority containing at least one node with that entry, guaranteeing the entry appears in every future leader's log.
Handling Log Divergence
When a leader crashes and a new one is elected, follower logs may diverge:
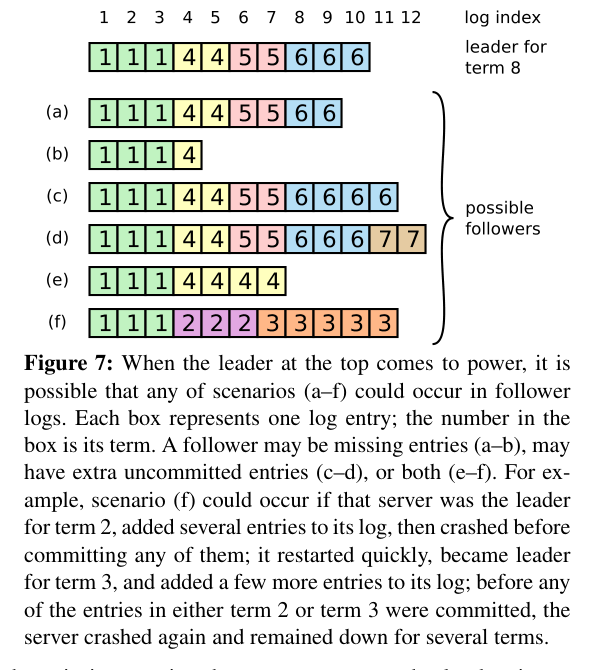
The new leader fixes this by sending AppendEntry RPCs that overwrite conflicting entries. It walks each follower's log backwards until finding a matching position, then replays forward. Entries that were never committed (never acknowledged to clients) are silently overwritten — no data loss from the client's perspective.
Implementation Notes
The full implementation is ~600 lines of Python. The trickiest part is the threading model. The election timer, heartbeat sender, and RPC handlers all run concurrently and share state (current_term, state, log, commit_index). Without careful locking, a timer firing mid-RPC produces subtle races.
The solution: a single lock guards all state mutations. This serializes all state transitions and makes the algorithm's invariants easy to verify.
What the Paper Gets Right
Raft is easier to implement correctly than Paxos precisely because it decomposes the problem. Leader election is fully separate from log replication. Term numbers give you a total ordering on time. The paper's Figure 2 is a complete specification — every state variable, every invariant, every condition under which each RPC is sent or rejected.
Reading Figure 2 carefully before writing a line of code is the right approach. Every bug I hit traced back to a condition I'd skimmed over on first read.
Algorithm Reference
